그리고 20시간 AI 특강을 들었는데 computer vision, nlp, 예측, 추천, 생성형 AI 등등
AI 기술 전반적인 개념 강의와 실습 코드들을 돌려보고 미니 프로젝트 3가지 중 1가지를 해서 제출하는 과정이었다
AI 관련 기술은 주단위로 새로운 기술이 나와서 강의도 매번 업그레이드 되는데
정말 따라가기가 무섭다... ㅠㅠ
특히 이번 강의에서는 MLOps 라는 모델 배포 관련 개념과 관련 기술인 bentoml이 가장 충격이었다
[공통 프로젝트 - 주제 선정 & 사용자 시나리오 작성]
AI 강의와 함께 팀빌딩과 프로젝트도 진행됐다
그런데 사실 팀끼리 회의할 시간을 거의 주지 않아서 다른 팀들은 아직 주제를 정하지 못한 곳이 많은 것 같았다
그래도 우리팀은 내가 낸 아이디어를 다들 좋게 생각해줘서 바로 주제를 정하고 서비스 명도 정하고
간단히 사용자 시나리오까지 이번주에 만들어 볼 수 있었다
금요일 점심에 원래 사용자 시나리오를 위한 회의를 진행하기로 했는데 문득, "내가 또 너무 일만 하고 있나?!" 하는 생각이 들었다. 그래서 급 회의를 취소하고 커피나 마시러 가자고 했는데 팀원들도 다들 좋다고 했다. 나는 내심 미안한 마음이 들어서 커피를 샀고 다들 어떻게든 돈을 보내주려 했지만 결국 받지 않았다. 그렇게 간단히라도 커피를 마시면서 이런저런 이야기를 나누고 나니 전보다 분위기도 좀 편해지고 의견도 더 자유롭게 나눌 수 있게 되었다는 생각이 들었다. 물론 나만의 생각일 수도 있지만 확실히 그렇게 느꼈다. 결국 모든 일은 사람들이 모여서 하는 것이고 언제나 팀원들과의 유대와 인간적인 친밀감은 성과를 위해서도 중요한 요인인 것 같다.
솔루션, 소프트웨어 영업 직무로 근무하면서 개발자들과 소통할 경우도 많고, 직접 판매하는 솔루션의 API를 연동해 보기도 하면서 은근 "코딩"을 해 볼 기회가 있었다.
하지만 체계적인 공부 없이 그때그때 필요한 것만 익혔던 나는 파편화 된 지식으로 오히려 모르는 것보다 더 위험한 "어설프게" 아는 코린이(코린이라고 하기에도 민망한)였다.
"요즘에는 Python도 옛날 언어이고 React를 배워야 한대요!"
내가 실제로 솔루션 영업직으로 근무할 때, 엘리베이터에서 동기에게 했던 말이었다. 그렇다 나는 프로그래밍 언어와 라이브러리도 정확히 구분하지 못하는 혼돈의 코린이였다.
그런 코린이를 이제는 "그럴듯한" 웹 앱을 풀스택으로 개발할 수 있게 성장시켜준, 값진 "나의" SSAFY 1학기를 정리해본다.
25년 6월, 서울캠퍼스 최종합격 메일을 받고 7월 2일, 입과 안내 메일을 받았다.
7월 8일(화)이 1학기 시작일이였는데, 시작 전부터 사전 과제로 강의도 들어오고 알고리즘 문제도 풀고, AI 과제도 줘서 쉽지 않은 1년이겠다는 느낌이 팍팍 오는 사전 준비 기간이었다.
정규 교육이 시작되는 첫 날 간단한 레벨테스트를 보고, 나는 비전공 파이썬트랙 과정의 서울 3반으로 배정받았다. 그리고 7/18일 까지는 AI 스타트캠프 기간으로 AI 아이디어 해커톤도 하고 앞으로 SSAFY 과정이 어떻게 진행되는지 교육 받고 적응하고 그러는 시간이었다. 이 때 간단한 CLI랑 git 사용법도 배웠는데 "스타트캠프"인 만큼 진짜 앞으로의 과정을 준비하고 적응하는 시간이었다. 개인적으로는 백준 계정을 만들고 github도 만들고 gemini도 구독 시작하고 그랬던 기간.
그렇게 적응기간이 끝나고 본격적인 공부와 테스트의 시간이 시작됐다.
싸피 1학기 교육과정은 웹개발에 필요한 여러 도구들과 알고리즘 등 지식이 필요한 것들을 학습하고 거의 매주 금요일마다는 관통 PJT라는 1학기 최종 프로젝트를 준비하는 시간으로 구성되어 있다. 그리고 14기부터 본격적으로 대폭 늘어난 AI 교육도 있다. 매번 하나의 과목에 대한 학습이 끝나면 테스트를 보는데 그렇게 총 10개의 과목평가와 6개의 월말평가를 봐야하고, 그 중 절반 이상을 pass 해야 1학기 수료가 가능하다. 추가로 알고리즘 역량을 평가하기 위한 "SW 역량 평가" 도 비전공자의 경우 IM수준 이상을 통과해야 한다. 새로운 과목을 배울 때는, 오전에 강의를 2시간 듣고 2시간 동안 배운 개념을 오후에 실습과 과제를 통해 익히는 과정으로 되어있다. 이 실습과 과제가 진짜 알차기 때문에 매일 주어진 2개의 과제와 8개의 실습을 모두 끝내면 당일 배운 개념들을 확실히 익힐 수 있었다.
그렇게 1학기 동안 배운 것들을 정리하면,
항목
기간
내용
1. Python
7/21 ~ 7/31 (약 2주)
python 문법, OOP
2. SW 문제해결 기본(알고리즘 기초)
8/4 ~ 8/22 (약 3주)
List, String, Stack, Queue, Tree
3. Web + AI 특강
8/25 ~ 8/28 (4일)
HTML, CSS, Bootstrap, Gemini CLI
4. SW 문제해결 응용(알고리즘 심화)
9/1 ~ 9/17 (3주)
브루트포스, 그리디, 백트래킹, 그래프 등
5. Django
9/18 ~ 10/2 (2주)
Template, Model, ORM, Form, 인증
6. AI 강의
10/10 ~ 10/30 (3주)
대학원 수준의 학문적 AI 강의,,, (교수님 진도가 너무 빨라여,,,)
7. DB
11/3 ~ 11/11 (6일)
SQL, M:1, M:M
8. DRF (Django REST Framework)
11/12 ~ 13 (2일)
DRF로 API 서버 만들기
9. JS
11/17 ~ 11/25 (5일)
JS 문법, Event, DOM조작, AJAX
10. Vue
11/26 ~ 12/11 (2주)
Vue 문법, Router, 상태관리
이정도 인 것 같은데 돌아보니 진짜 많은 것들을 알차게도 배웠다!! ㅋㅋ
12/11 이후에는 취업박람회 일정이 있었고 최종 관통 프로젝트 개발과 경진대회를 진행하고 1학기가 마무리 되었다.
사용자가 선택한 영화의 줄거리와 배우, 감독 정보를 기반으로 TMDB 데이터를 필터링하여 추천 영화 제공
TMDB API 와 YOUTUBE API를 활용하여 영화의 예고편 제공
리뷰 커뮤니티: 영화별 평점 및 상세 리뷰 작성, 사용자 간 소통을 위한 소셜 피드 및 마이페이지 기능 제공.
RESTful API: Django를 활용해 프런트엔드와 백엔드를 완전히 분리하여 데이터 교환 효율성 극대화.
아키텍처
- ERD
- Vue Tree
3. 기술적 도전과 해결 과정 (Trouble shooting)
1. 프로젝트에 사용할 데이터 취득과 전처리 문제
프로젝트에 사용할 영화 데이터를 구하고 전처리 하는 과정에 많은 시간을 투자했고
TMDB API로 최신 인기 영화 데이터를 호출해서 사용하기로 결정하기까지 많은 의사결정을 거쳤음.
1. Kaggle에 TMDB 1M 데이터 사용
가장 처음 선택한 데이터는 Kaggle에 있던 공개된 데이터로 출시일, 유명도, 평점 등을 기준으로 최신영화, 평점이 일정 점수 이상인 영화 등을 필터링 하고 Null 값과 비어있는 값 등을 전처리해서 약 20,000개의 데이터를 확보, 사용했음.
그러나 데이터가 모두 영어여서 한국인 사용자를 가정하고 진행하는 프로젝트 특성 상 UI, UX적인 측면에서 문제가 있었음.
2. TMDB API 사용
TMDB API 중 popular를 이용하여 평점이 높은 영화 데이터 1차 호출, 이후 응답받은 데이터 중 TMDB ID를 이용해 detail과 actor 정보를 추가로 요청해서 최종 데이터 수집
이후 포스터 URL을 완성하고 배우 정보를 5명 까지만 수집하는 등 전처리 과정을 거쳐 최종 1,000개 데이터 확보(data_preprocessing.py 파일 참고)
한글로 된 최신 영화 데이터들을 확보할 수 있었으나 데이터 수가 부족한 문제가 있었음. -> 추천 기능 약화
3. TMDB API 사용 (데이터 수 증가)
초기 수집하는 데이터 수를 증가하여 전처리 이후 약 2,700개 데이터를 확보. -> 추천 기능 강화
그러나 overview(줄거리) 컬럼에 빈 문자열이 제대로 필터링 되지 않았던 것을 발견
4. TMDB API 사용 (데이터 수 증가 및 전처리 강화)
최종적으로 초기 6,000개 데이터를 불러온 후 전처리를 좀 더 꼼꼼히 진행하고 최종적으로 약 3,700개 데이터를 확보 및 사용
이로 인해 가장 양질의 데이터를 확보하여 추천 품질도 가장 좋았으며, 기본 UI, UX 측면에서도 가장 좋은 데이터 확보
2. 생성형 AI를 API로 연동하여 닉네임 추천 받기
간단한 작업이라 생각하여 gemini-2.0-flash 모델을 사용하고 프롬프트에도 "한글만 사용하라", "5~12자로 생성하라", "특수문자를 사용하지 말아라" 등 꼭 필요한 요청사항 외에 다양한 요구사항을 넣고 길게 작성하였음
그 결과 생성 시간도 30초 정도로 매우 길고 계속 비슷한 닉네임만을 추천해서 결과가 매우 만족스럽지 못했음
이에 모델을 gemini-2.5-flash로 변경했는데 그래도 크게 성능이 개선되지 않았음
결국 gemini-2.5-pro로 최종 결정하고 프롬프트도 꼭 필요한 것들로만 작성해서 최종 생성 시간을 10초 정도로 줄일 수 있었음
간단한 기능이라 프롬프트 대충 작성해서 api로 요청 받아서 결과값 띄워주면 될 거라고 생각했는데 생각보다 정교한 프롬프트 작업과 모델 선정이 필요했음
3. 배포하기(배포 쉬워졌다며,,, 왜 이렇게 어려운건데,,,)
1. CloudType(back) + Netlify(front)
- github repository를 연동해서 바로 배포하는 방법을 사용했는데 프로젝트 repository에 back과 front가 둘 다 들어있고 각각 다른 툴로 배포하려고 할 때는 work directory를 잘 설정해줘야 함!!(은근 까먹음) - django secret key, 사용한 여러 API key 등 환경 변수 세팅 잘 해줘야 함(당연하지만 은근 까먹음) - migrate나 gunicorn 실행을 위한 Run command 설정 해줘야 함 - front 배포할 때는 코드에 local로 작성한 요청 주소들을 배포한 back요청 주소로 모두 교체해야 함 (처음 코드를 작성할 때부터 배포할 때를 고려해서 하드코딩하지 말기 ㅠㅠ) - front와 back이 서로 통신할 수 있도록 django settings.py에서 ALLOWED_HOST, CORS, CSRF 등 설정해줘야 함 (이게 진짜 초보자에게 어려운 부분인듯 ㅠㅠ)
이런 여러가지 사항들을 Gemini를 통해 알아가면서 거의 4시간 만에 배포에 성공...했으나...!
무료 티어에서 제공하는 메모리가 너무 작아서 추천 기능에서 out of memory 발생!! 백엔드 서버가 강제로 꺼짐!!!!
뿐만 아니라 CloudType는 무료티어일 경우 매일 한 번씩 강제로 서버가 꺼져서 다시 켜줘야 하고 둘 다 무료사용량을 테스트 하는 동안 전부 사용해버려서 아예 새로운 조합으로 다시 배포해보기로 결정
2. Supabase(DB) + Koyeb(back) + Vercel(front)
DB가 없으면 back 서버가 켜질때마다 DB를 migrate 해야하고 기존 데이터도 모두 날아가니까 다시 하는 김에 DB도 해보기로 함
배포툴마다 UI가 달라서 "환경 변수 설정하는게 어디있지...?", "run command는 어디에..?", "요청 주소는 뭐지" 등등 조금 헤매기는 했지만 일단 기본 설정은 한 번 해봤다고 전보다는 조금 빠르게 했음
그러나 새롭게 추가한 Supabase에 데이터를 적재하는게 생각보다 쉽지 않았음ㅠㅠ
거기에 프론트랑 백엔드랑 기본적인 통신조차 자꾸 실패하니까 배포따위 안해버리고 싶었지만
거의 6시간 만에 DB에 테이블 생성(데이터 없음), 백엔드 서버 배포, 프론트 배포, 백엔드와 프론트 통신 성공(회원가입 후 로그인 성공 (근데 겁나 느림))까지 할 수 있었다,,,
그 험난했던 여정은 gemini가 아래와 같이 정리해줬다
🚩 1단계: 데이터베이스 연결 및 로컬 접근 시도 로컬 컴퓨터의 데이터를 Supabase 클라우드 DB로 옮기려 했으나, 네트워크 계층의 장벽에 부딪혔던 시기입니다. - 시도: Git Bash 및 로컬 Django 설정을 통해 Supabase에 loaddata 시도. - 발생 에러: - bash: !1204: event not found: 비밀번호 내 특수문자(!)가 Bash 히스토리 확장 기능을 건드려 발생. - django.db.utils.OperationalError: could not translate host name: 로컬 ISP(인터넷 서비스 제공업체)의 DNS가 Supabase 도메인을 해석하지 못함. - Connection timed out (10060): IP 주소로 직접 접근했으나 로컬 방화벽/네트워크에서 DB 포트(5432) 접속 자체를 차단함. - 해결방안(해결 못함): 비밀번호 인코딩(%21) 적용 및 로컬 시도 중단. 대신 이미 DB와 통신이 검증된 Koyeb 서버 내부에서 해결하기로 전략 수정.
🚩 2단계: 백엔드 서버 구축 및 헬스 체크 통과 Koyeb에 Django 서버를 올리는 과정에서 서버 부팅과 데이터 적재가 충돌했던 시기입니다. - 시도: Koyeb Run command에 loaddata와 gunicorn 실행 명령을 동시에 넣음. - 발생 에러:TCP health check failed on port 8000: 3,800개가 넘는 데이터를 넣느라 Gunicorn이 정해진 시간 내에 응답 하지 못해 Koyeb이 서버가 죽었다고 판단하고 강제 종료함. - 해결: loaddata 명령을 분리하고 서버 실행(gunicorn)만 집중시켜 Healthy 상태를 먼저 확보함.
🚩 3단계: 프론트엔드-백엔드 연동 및 통신 이슈 Vercel에 올린 프론트엔드와 Koyeb 백엔드가 서로 대화하게 만드는 과정입니다. - 시도: Vercel 환경 변수에 Koyeb URL을 설정하고 API 요청. - 발생 에러: - 404 Not Found (Vercel 도메인 포함): 요청 주소가 https://sync-movie.vercel.app/https://urban-sheila... 처럼 형성 됨. 프론트엔드에서 상대 경로로 인식해 자기 자신(Vercel)에게 요청을 보낸 상황. Failed to load resource: CORS 설정 미비로 인해 브라우저가 보안상 요청을 차단함. - 해결:Vercel 환경 변수에 https://를 명확히 포함하여 절대 경로로 수정. settings.py에서 CORS_ALLOW_ALL_ORIGINS = True 및 미들웨어 순서 조정을 통해 통신 허용.
✅ 요약: 현재까지 해결된 것 vs 남은 숙제
상태
항목
내용
성공
네트워크 통로
프론트(Vercel)에서 백엔드(Koyeb)로 요청이 전달됨
성공
서버 상태
Django 서버가 Koyeb에서 Healthy 상태로 구동됨
미결
데이터 적재
api_data.json의 영화/장르/배우 데이터가 DB에 아직 없음
원래 하려고 했던 추천 기능은 테스트 해보지도 못하고 두 번째 배포 시도도 상처 뿐인 마음과 함께 종료,,,
이후 Koyeb서버 빌드 후 console에서 loaddata를 하려고 했는데 그것도 메모리 문제로 안돼서 데이터를 적재하는 별도의 python 코드를 짜서 push 하고 바로 loaddata 하는 대신 새로 만든 fast_load.py 파일을 실행하는 방법으로 데이터 적재를 시도했다
그런데 이것도 장르별, 배우별, 영화별로 데이터를 넣으려니 그것도 메모리가 부족해서 100개 단위로 넣는 방법을 시도했다가 그것도 계속 멈춰서 10개씩 시도하는 방법으로 반복 시도...
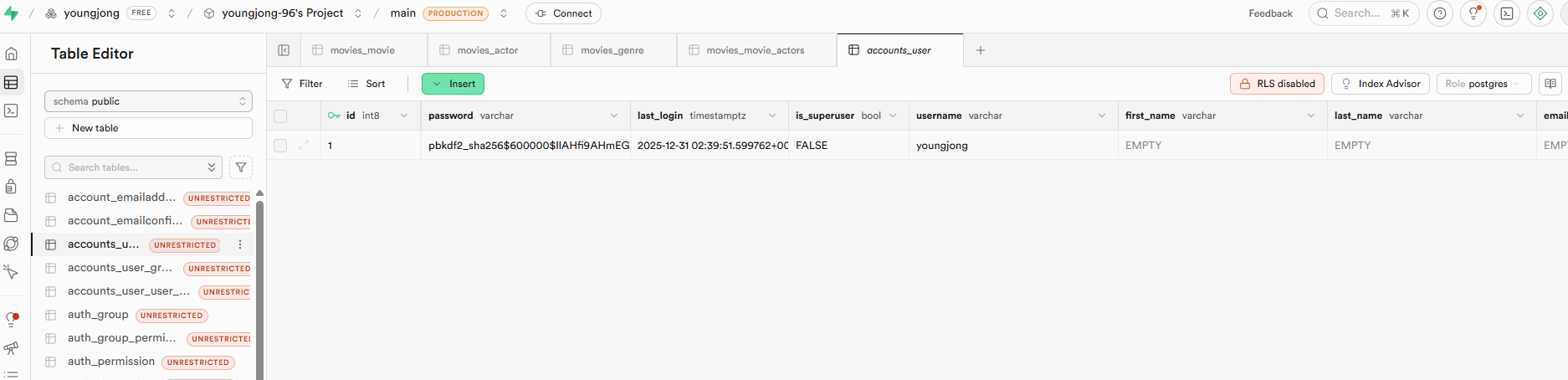
그 결과 전체 데이터의 일부인 장르(19개), 배우(852개), 영화(213개) 정도의 데이터를 supabase에 적재했다
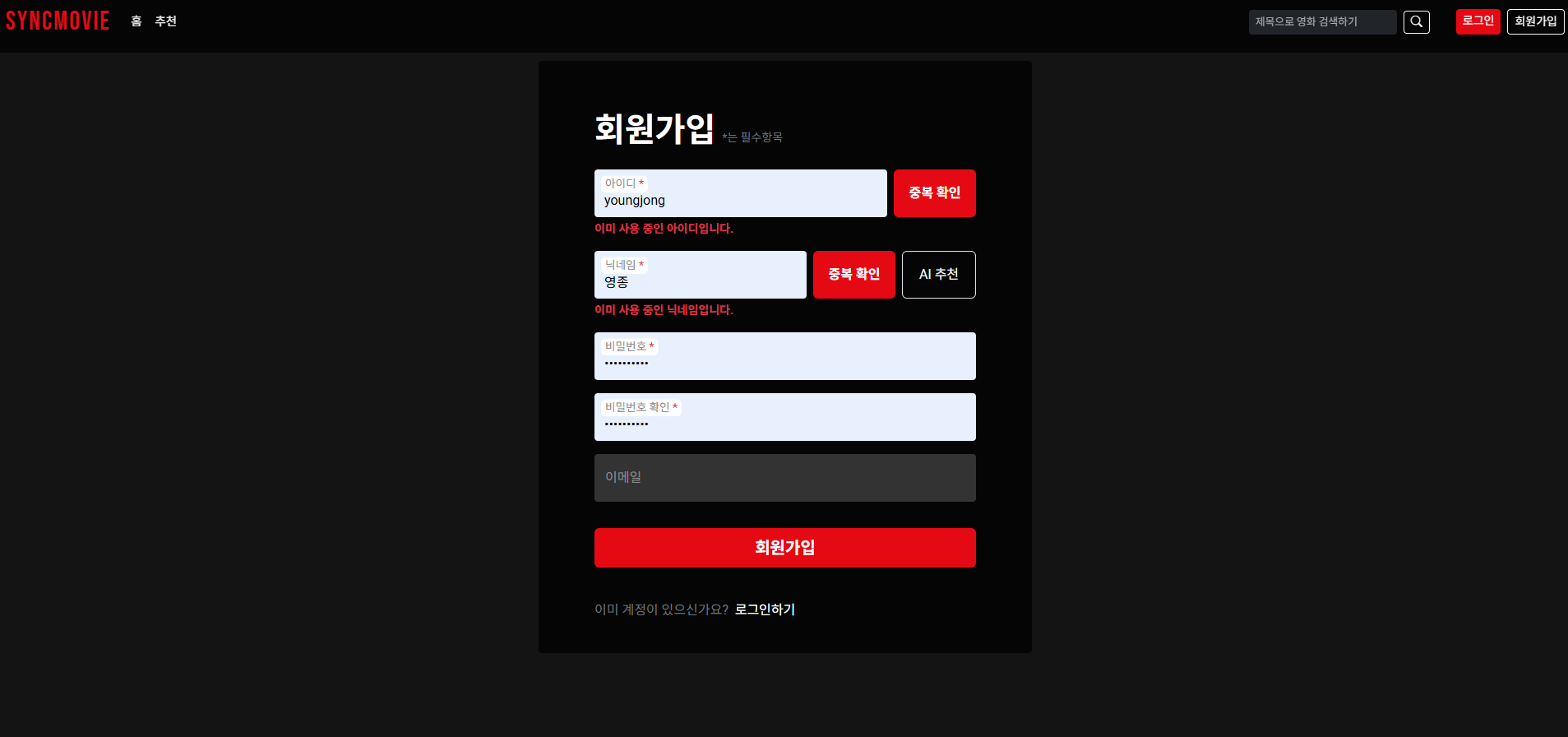
그리고 배포한 사이트에서 회원가입 후, 로그인까지 잘 되는 것을 확인했으나
회원가입 페이지백엔드 서버 로그 기록supabase에 새롭게 들어간 user data적재한 data에 M:M 관계 데이터가 들어가지 않아서 메인페이지에서 영화 데이터를 불러오지는 못했다...데이터 로딩에 실패한 메인 화면...결과적으로 배포는 실패했지만 리소스 부족 때문이라고 여기며좀 더 공부해서 다음 프로젝트에서 제대로 해보는 것으로 마무리했다끝까지 해보고 싶기도 했지만 더 중요한 공부들이 많고 여기에 시간을 더 쓰면 안 될 것 같아서 이건 여기서 끝!
4. 협업 및 프로젝트 관리
Git 규칙
branch 운영 방식
master branch에 직접 수정 x
yj, hw 브랜치로 분리해서 작업 후 이상 없을 시 master branch로 merge
최종 merge전 팀원과 상의하고 conflict 발생 시 협의 후 코드 선택
commit 기록 내역 원칙
개발 기능 단위로 commit 진행
개발 중 잘못된 사항이 발견되어 수정한 경우 동일한 commit내용에 _수정을 붙여서 commit
commit 내용 양식: 요구사항번호[_기능명][_수정(수정한 경우)]
기존에 많이 알려진 검증된 branch 전략들은 모두 무시한 채 단순히 master 브랜치는 건들지 말고 니꺼 내꺼 브랜치 만들어서 필요 시점마다 협의해서 merge하자! 전략 선택! 그 결과 의외로(?) 아무런 문제 없이 원활한 협업과 코드 관리가 이루어졌는데 이건 순전히 함께 개발한 인원이 2명으로 매우매우 적고 팀워크가 잘 맞았기 때문이라고 생각 commit 기록 원칙도 처음에 정했는데 정작 개발하면서 거의 지켜지지 않았음...ㅋㅋㅋ
하지만 이런 모든 전략들과 원칙은 결국 "원활한 협업"을 위한 것이기 때문에 이번 프로젝트에서는 중요도가 좀 떨어졌던 부분이라고 생각하고 앞으로의 프로젝트에서는 필요하다면 철저히 잘 지킬 수 있을 것이라 생각함
5. 잘한 점 및 아쉬운 점 (Self-Reflections)
잘한 점
기획부터 백엔드, 프론트 개발, 배포까지 모두 직접 진행함으로 모든 과정을 이해할 수 있었던 것
티어와 자주 소통함으로서 원활한 협업을 진행한 것
error 메세지를 분류하여 사용자가 현재 상황을 인식할 수 있도록 하고(진행중이여서 기다리면 되는지, 아니면 문제가 있어서 뭔가를 수정해야 하는지 등) 다음 행동을 가이드 해서 UI, UX를 개선해 나간 것
처음 데이터를 수집한 것에서 만족하지 않고 계속해서 더 양질의 데이터를 얻기 위해 찾아보고 전처리 한 것
아쉬운 점
개발 기간이 짧아서 정말 홈페이지의 기본적인 틀만 잡고 기능들도 간단한 것들 밖에 추가하지 못했던 점이 아쉬웠다
생성형 AI로 닉네임만 추천해주는 것이 아니라 프로필 이미지도 추천해주는 기능도 추가하고 1달 주기로 TMDB API에서 최신 영화 데이터를 자동으로 불러와서 영화 데이터들을 자동으로 업데이트 하도록도 만들고 싶었는데 시도해 보지 못한 것이 아쉽다
하지만 만약 다 구현했다면 배포 과정에서 또 어떤 지옥을 맞이했을지 상상만 해도 아찔하다,,,
그리고 개발 초반에는 문서화 하는 것에도 집중했는데 점점 시간이 없어지면서 문서화에 들이는 시간이 줄어들었던 게 조금 아쉽다
개발에 투자하는 시간과 문서화에 투자하는 시간이 어느 정도 되어야 가장 효율적이고 균형 있는가는 항상 고민이겠지만
이번 프로젝트에서는 문서화에 투자했던 시간이 많이 부족했던 것 같기도 하다
6. 마무리하며
SyncMovie는 나의 첫 그럴듯한 프로젝트로, 프로젝트 기획부터 배포까지 모든 과정을 직접 해볼 수 있었던 소중한 프로젝트였다
비록 개발 기간도 짧고 함께한 인원도 적은 토이프로젝트 수준이었지만 풀스택으로 모든 과정을 경험해보고 협업도 해보면서 앞으로 있을 프로젝트를 성공적으로 해나가기 위한 훌륭한 초석이었다고 생각한다
제일 재밌었던 건 Gemini-2.5-pro로 닉네임 추천 기능 완성하고 닉네임 추천 받았을 때 재밌는 닉네임이 나왔을 때,
제일 기억에 남는 건 인증과 권한 관리 부분을 개발할 때, 회원가입과 로그인 과정부터 UI, UX적인 측면에서 개선할 수 있는 부분이 얼마나 많고 다양한지 깨달았을 때,
Lovable(러버블)은 한 마디로 '말만 하면 웹 서비스를 실제로 만들어주는 AI 개발 플랫폼'이다.
기존의 노코드(No-code) 툴들이 미리 정해진 블록을 조립하는 방식이었다면, Lovable은 사용자가 채팅으로 요구사항을 설명하면 AI가 직접 프론트엔드부터 백엔드, 데이터베이스까지 연결된 실제 코드를 짜서 웹 앱을 구축해 준다.
1. 주요 특징
풀스택 개발: 화면 디자인(React)뿐만 아니라 데이터 저장(Supabase 연동), 사용자 인증(로그인), 비즈니스 로직까지 한 번에 생성한다.
실제 코드 기반: 생성된 결과물은 단순한 디자인 시안이 아니라, 언제든 다운로드하거나 GitHub로 내보낼 수 있는 '진짜 소스 코드'를 만들어낸다.
실시간 미리보기 & 수정: 채팅창 옆에 작업 중인 앱이 실시간으로 떠 있어서, "이 버튼을 빨간색으로 바꿔줘", "검색 기능을 추가해줘"라고 말하면 즉시 반영된다.
Vibe Coding: 복잡한 문법을 몰라도 "이런 느낌의 앱을 만들어줘"라는 식의 대화만으로 개발이 가능해 '바이브 코딩' 도구로도 불린다.
2. 어떤 때 사용하면 좋은가요?
Lovable은 속도와 검증이 필요한 상황에서 강력한 위력을 발휘한다.
아이디어 검증(MVP 제작): 새로운 사업 아이디어가 떠올랐을 때, 며칠씩 고민하지 않고 단 몇 시간 만에 실제로 작동하는 시제품을 만들어 고객 반응을 살필 수 있다.
내부 도구 제작: 사내에서 사용할 대시보드, 고객 관리용 CRM, 간단한 예약 시스템 등 복잡한 설계가 필요 없는 도구를 개발자 도움 없이 직접 만들 때 유용하다.
개발자 생산성 향상: 전문 개발자가 반복적인 '보일러플레이트(기초 코드)'를 짜는 시간을 줄이고, AI가 만든 초안을 바탕으로 세부 로직만 수정하고 싶을 때 좋다.
랜딩 페이지 제작: 마케팅용 페이지나 이벤트 페이지를 고퀄리티의 디자인과 함께 빠르게 배포해야 할 때 효과적.
직접 사용해보자
홈페이지 접속해서 구글 계정으로 로그인만 하면 바로 무료버전으로 사용해 볼 수 있다
로그인 후 메인페이지(대시보드)
메인페이지에서는 사이드바에서 여러 메뉴들을 선택할 수 있고 중앙에 있는 프롬프트에 원하는 요청을 입력해서 바로 프로젝트를 시작할 수 있다.
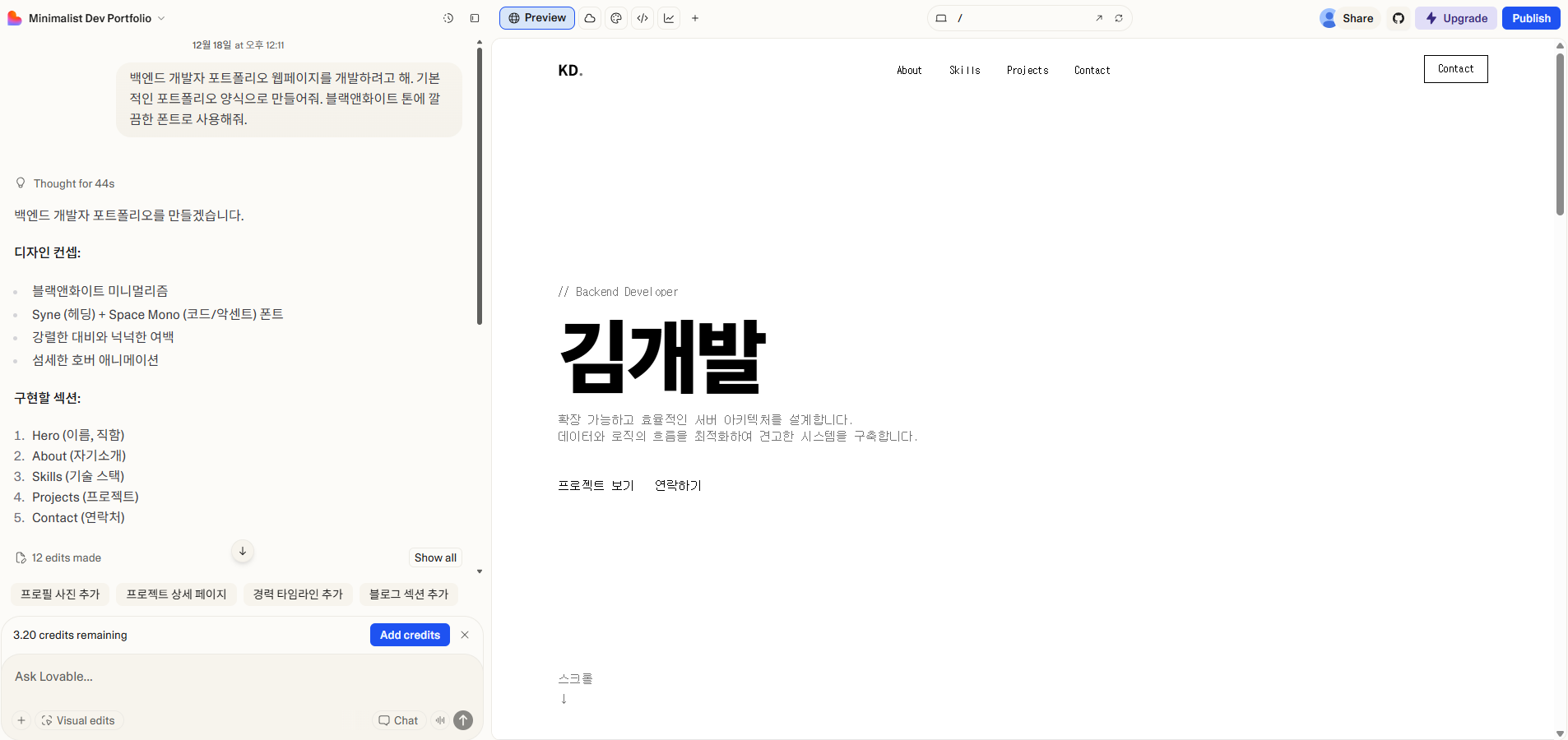
백엔드 개발자 포트폴리오 웹페이지를 개발하려고 해. 기본적인 포트폴리오 양식으로 만들어줘. 블랙앤화이트 톤에 깔끔한 폰트로 사용해줘.
위와 같이 프롬프트에 요청하니까 바로 웹 페이지 하나를 뚝딱 만들어주는데 단순히 디자인적인 요소만 볼 수 있는게 아니라 Preview탭에서 실제 동작을 확인할 수 있었다.
만들어주는 속도는 엄청 빠르진 않았지만 기다릴만한 정도?
간단한 포트폴리오 페이지 정도는 5분 이내로 완성했다.
그리고 디자인만 해주는건줄 알았는데 실제 동작하는 웹페이지를 만들어 줌!
프로젝트에는 Preview, Cloud, Design, Code, Analytics, Security, Speed 탭이 있고 각각 관련된 기능들을 사용할 수 있다.
Preview: 실제 브라우저에서 동작하는 것처럼 만들어진 웹 페이지를 확인할 수 있음
프롬프트 요청 후 나오는 화면(Preview 탭)
Cloud: Built-in-backend를 연동하거나, LLM을 연동할수도 있고, 권한 설정 등 배포를 위한 설정들을 하는 곳이다.
Cloud 탭 - 다양한 옵션 구체적 설정 가능구체적 권한 설정도 가능함..!
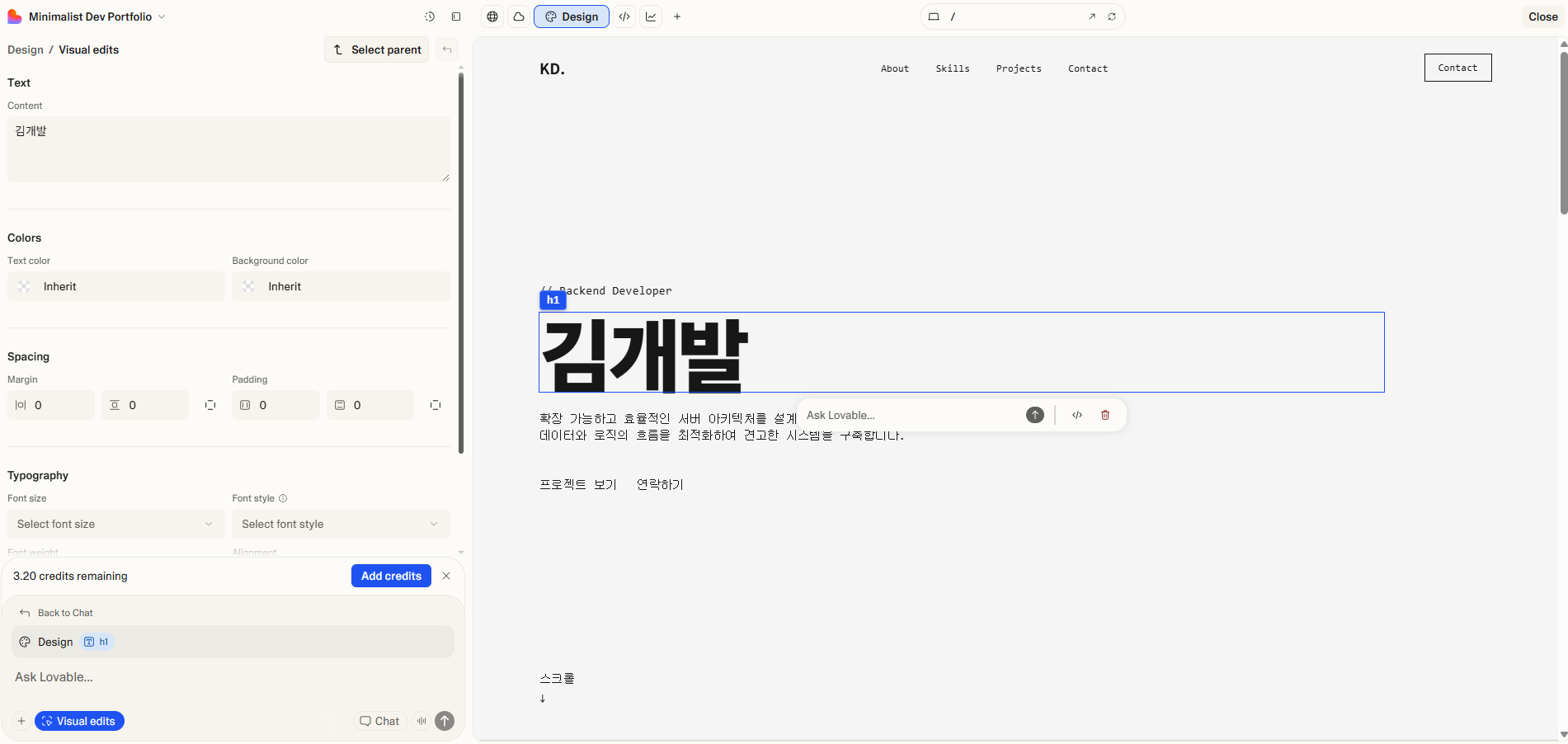
Design: 원하는 테마를 전체적으로 적용하거나 웹페이지 요소들을 PPT를 수정하는 것처럼 수정할 수 있는 페이지이다. PPT처럼 웹페이지를 바로 수정하는게 매우 신기한 경험이었음
PPT 수정하는 거처럼 수정가능하고 요소에 대한 AI 요청도 가능
Code: 만들어진 코드를 확인할 수 있는 페이지로, 코드를 다운로드 받을 수 있다
실제 코드들을 확인할 수 있음. AI가 다음 작업으로 할 만한 것도 추천해줌.
Analytics: 배포한 웹페이지에 대한 분석을 제공.
얼마나 정확한지는 모르겠으나 다양한 분석결과 제공 (배포하자마자 US visitors가 4명이라고 나오는데 bot인가...)
Security: 보안 취약점을 파악해서 알려주고 고치는 것도 제공.
Speed: 웹페이지에 관련된 다양한 분석을 제공. 탭을 클릭하면 해당 이슈를 보여줌. SEO도 있음.
정말 코딩을 하나도 몰라도 완성된 서비스는 아니더라도 실제 동작하는 프로토타입을 만드는 수준으로는 너무 좋은 것 같다. 대시보드에서 프로젝트 별로 관리가 가능한 것도 사용자 편의성에서 아주 좋은 듯. 기존에 사용하던 gemini 로 어느정도 대체할 수 있을 것 같지만 배포가 쉽게 가능하고, 여러가지 보고서를 제공하고 쉬운 UI로 개발이 가능하다는 점에서 차별성이 있는 것 같다. 다만, 매일 5credits 를 제공하는데 무료 크레딧 만으로는 정말 테스트만 가능했다. 개발자보다는 기획자들에게 더 유용한 AI 서비스인 것 같다.